Background
Context Engineering and RAG
Section titled “Context Engineering and RAG”Context engineering is the process of determining what information a Large Language Model (LLM) should receive as context at inference time. An LLM’s output depends critically on the relevance, structure, and scope of this context, which may be provided through prompts, memory mechanisms, tool interfaces, or retrieval-augmented generation. While modern AI systems often use a combination of these techniques, this project focuses specifically on RAG, as it is the dominant approach for grounding LLMs in large, private, and evolving knowledge bases.
Within RAG systems, retrieval refers to selecting relevant text from a knowledge base, such as documentation or a code repository. This selection is commonly performed through direct lookup, keyword search, or semantic search using vector embeddings. However, LLMs cannot reliably answer domain-specific queries unless the relevant knowledge is provided in machine-readable, well-scoped form. In practice, organizations typically store knowledge in long documents that mix unrelated topics. When retrieval surfaces entire documents, relevant information becomes buried within irrelevant content, forcing the model to reason over excessive context. Because LLMs do not reliably prioritize relevant information within long contexts and often exhibit positional biases that favor content near the beginning or end of the context window1 their ability to extract the necessary information is significantly hindered.
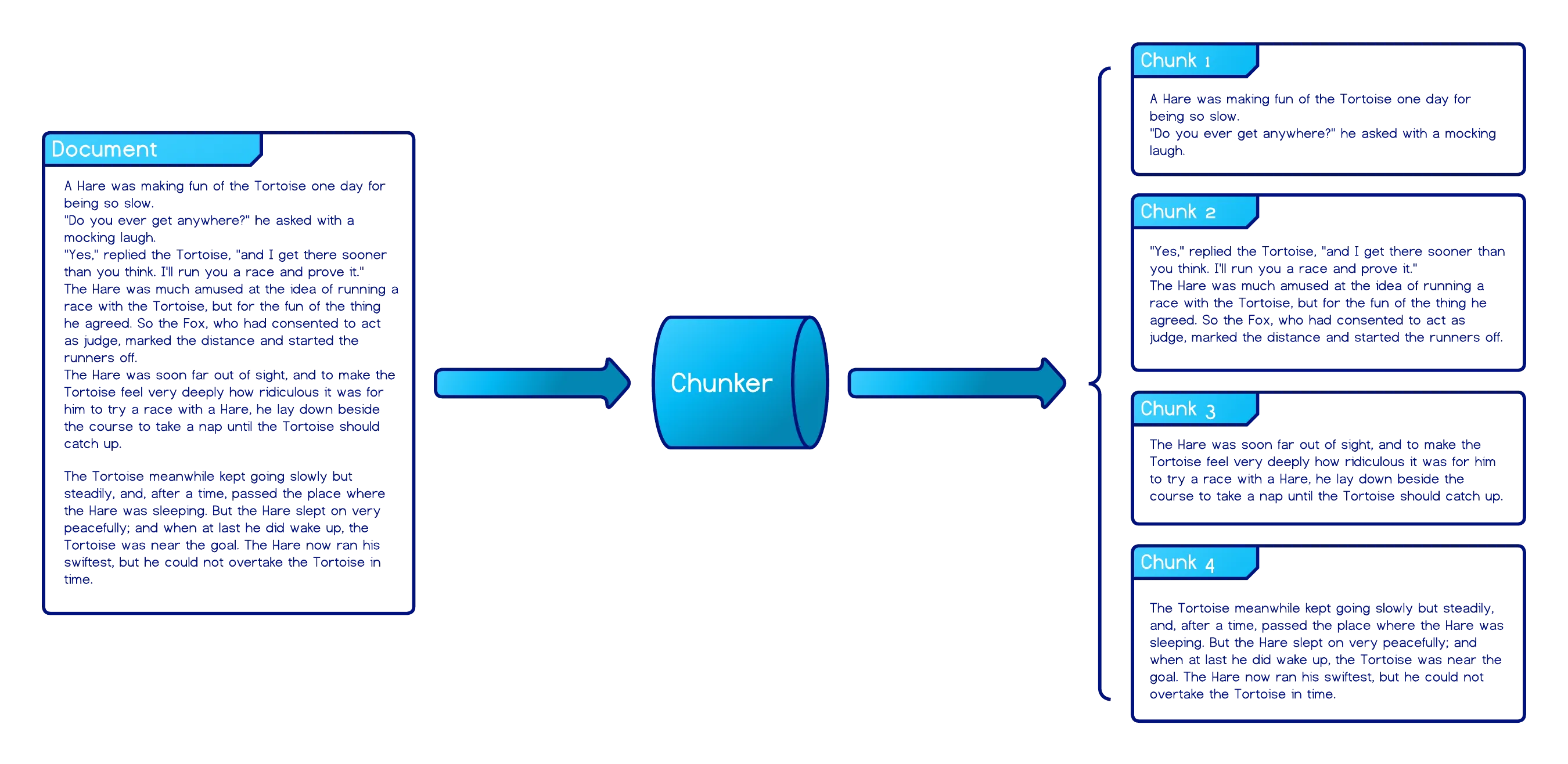
To enable precise retrieval, a knowledge base must therefore be structured so that retrieval can isolate and return smaller, focused segments from long passages. Chunking is the primary mechanism that enables this selective retrieval. RAG pipelines prepare documents as smaller, well-defined segments, i.e., chunks, that can be embedded and retrieved individually. By operating over chunks rather than entire documents, retrieval systems can surface targeted context that is both semantically relevant and efficiently consumable by downstream models.
In practice, RAG pipelines convert raw documents into retrieval-ready chunks through an AI-focused ETL process that:
- Extracts files from source systems,
- Processes text (e.g., Unicode normalization and whitespace cleanup),
- Chunks documents into segments,
- Embeds each chunk as a vector representation, and
- Loads the chunks and their vector embeddings into a vector store.

Once loaded, these chunks become the atomic units of retrieval. The quality of these units, and the boundaries that define them, directly determines what information can be retrieved, how much irrelevant context is introduced, and ultimately how effectively the LLM can reason over the provided context.
Chunking
Section titled “Chunking”In RAG data pipelines, chunking directly affects retrieval performance because embeddings are generated, indexed, and retrieved at the chunk level. By controlling the semantic density of each chunk (i.e., how many unrelated concepts it contains) and its structural integrity (i.e., whether chunk boundaries align with natural textual units such as sentences or paragraphs), chunking directly determines how effectively relevant information can be surfaced and retrieved.
It is important to note that chunking strategies are constrained by the structure and quality of their input text. Poorly formatted documents containing OCR artifacts, incorrect line breaks, excessive noise, or interleaved unrelated content will produce incoherent chunks regardless of the chosen chunking strategy. Therefore, chunking effectiveness depends critically on both strategy design and upstream text preprocessing quality.
Assuming the input text is reasonably well-formed and pre-processed, there are three major reasons why proper chunking is important for applications involving vector databases or LLMs:
- Fitting context within model limits - Embedding models have strict maximum context window lengths, and chunking ensures that each piece of data fits within these limits so that it can be embedded effectively.
- Improving search and retrieval - Embedding models represent each chunk as a single vector. If a chunk mixes multiple unrelated topics, the embedding becomes a blurred average of multiple meanings, producing noisy and inaccurate retrieval. Well-formed chunks stay focused and coherent, leading to more accurate similarity search, cleaner context, and thus better grounding during generation.
- Reducing hallucinations and optimizing context - Though many modern LLMs have large context windows, feeding them unchunked or overly long context can cause concept conflation and hallucination. Concise and relevant context improves LLM performance and frees up more of the context window for valuable prompt components such as detailed instructions, persona information, or few-shot examples.2
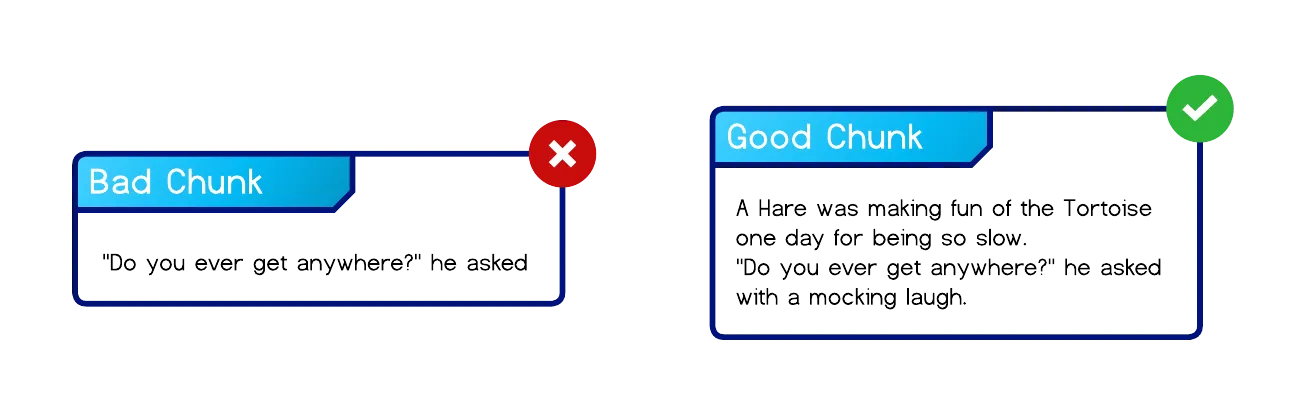
The challenge of chunking lies in finding an appropriate chunk size that is large enough to contain meaningful information for search and retrieval, yet small enough to improve LLM performance and reduce latency for compute-intensive operations such as RAG and agentic workflows. In addition, each chunk should remain structurally and semantically coherent, i.e., its boundaries should not split words, sentences, or other logical units.
Chunking strategy selection is critical for RAG applications that rely on fine-grained semantic retrieval over large, heterogeneous corpora with strict relevance and completeness requirements. Such applications include documentation search, internal knowledge assistants, compliance tooling, and agentic workflows that handle open-ended or exploratory queries. In these systems, retrieval quality depends on isolating coherent semantic units from long documents while preserving enough surrounding context for accurate reasoning.
Chunking is particularly important in workloads where missing or fragmented context can lead to incorrect conclusions. For example, fraud detection and compliance analysis systems often retrieve segments from lengthy call or chat transcripts. Overly aggressive chunking can fragment critical evidence, while overly coarse chunking can bury relevant signals within irrelevant content. Optimal chunk boundaries must therefore balance contextual completeness with retrieval precision, ensuring downstream models receive complete, relevant context for reliable decision-making.
Chunking Strategies
Section titled “Chunking Strategies”To address chunking challenges, various chunking strategies have emerged, each with distinct trade-offs in complexity, performance, and cost. Specifically, chunking strategies describe both how text is split and how those resulting chunks are adjusted through configurable parameters. Greg Kamradt, the creator of semantic chunking,3 categorizes chunking techniques into five levels of increasing sophistication:4
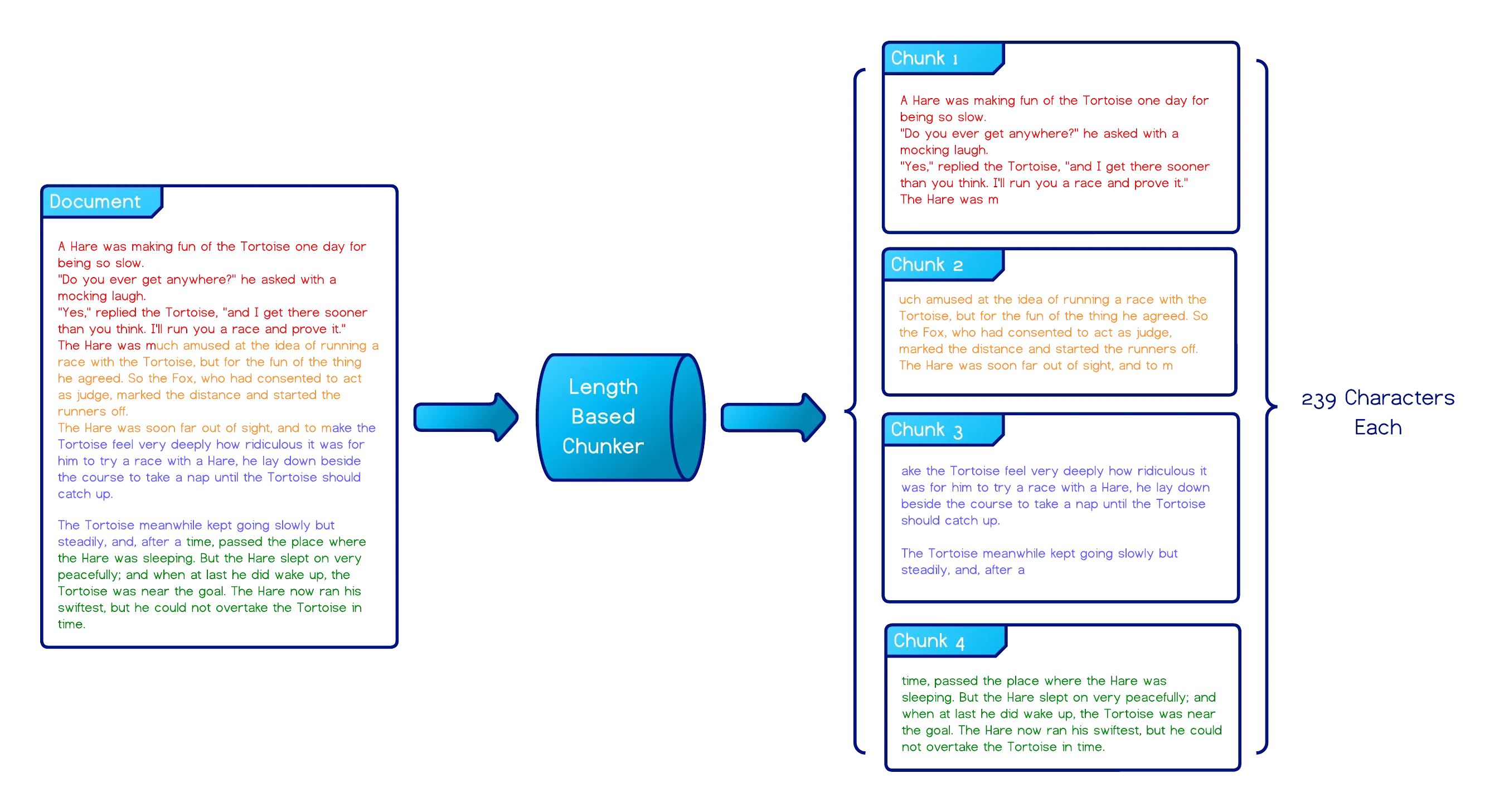
- Length-Based Chunking - The most basic approach, which splits text based on a character or token count without regard for structure or meaning. Some implementations (e.g., LangChain’s
CharacterTextSplitter) first split on a separator like\n\nand then merge the resulting pieces up to the targetchunk_size.
-
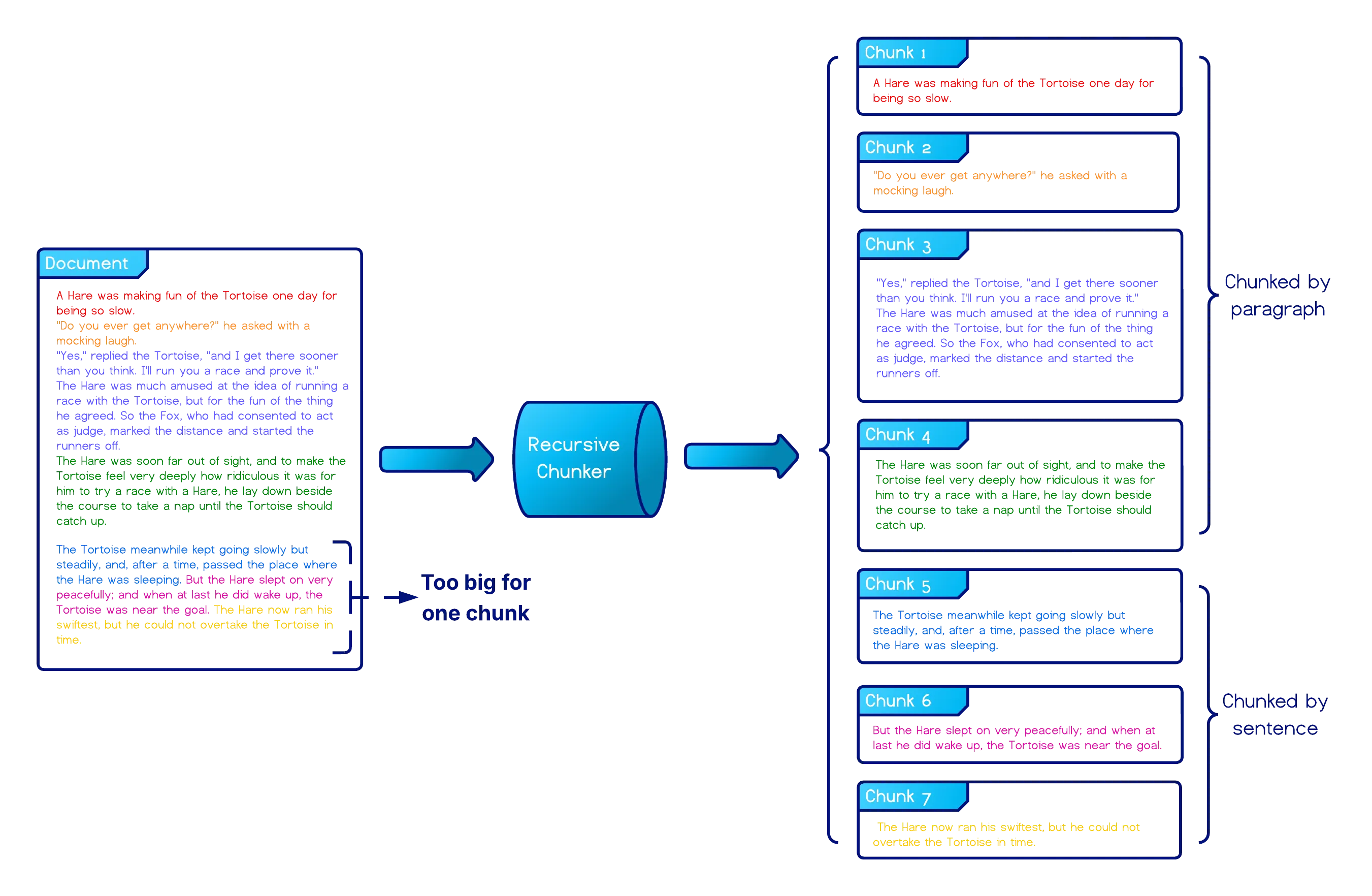
Recursive Chunking - A structure-aware method that splits text hierarchically using predefined separators (e.g.,
"\n"for paragraphs," "for sentences, and""for words). It attempts higher-level splits first, falling back to lower-level ones when a chunk exceeds the configuredchunk_size. -
Document-Type-Specific Chunking - A specialized form of recursive chunking that is tailored to different document formats such as PDF, Markdown, and code, respecting the syntactic and formatting rules native to each document type.
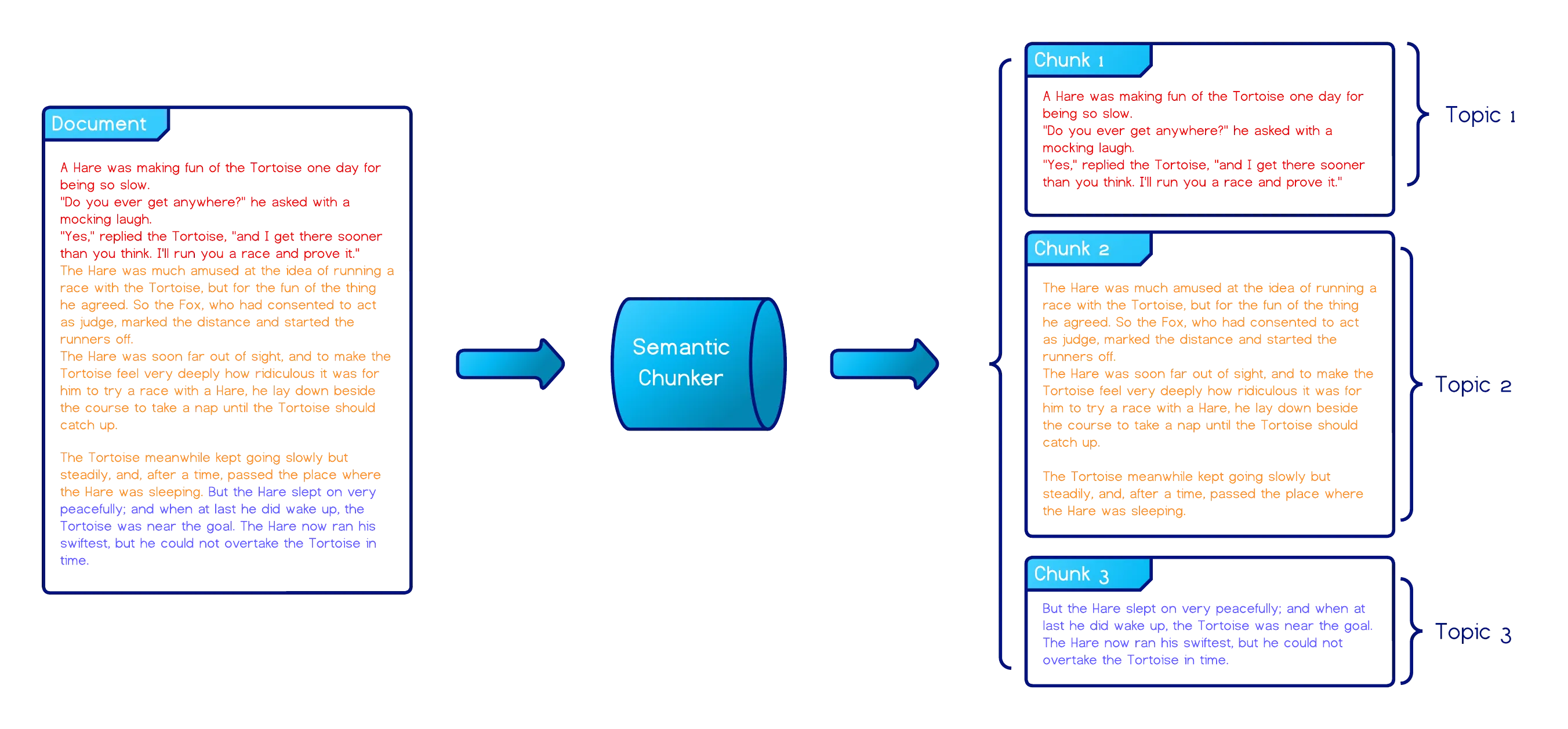
- Semantic Chunking - A content-aware method that groups semantically related text units (usually sentences) into coherent chunks by comparing the embeddings of adjacent text units. This approach produces more coherent, context-preserving chunks, but is also more computationally expensive.
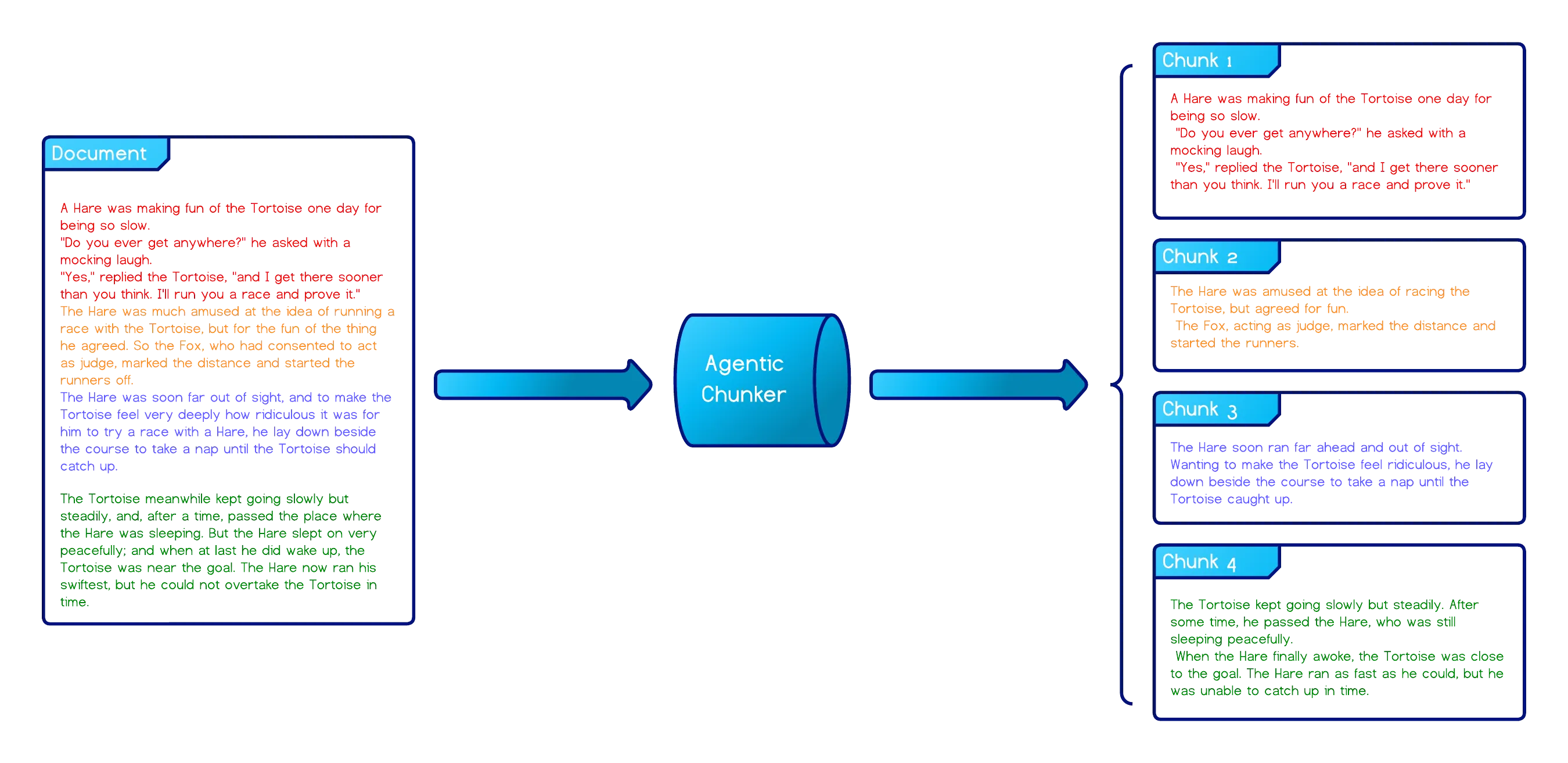
- Agentic Chunking - An LLM-driven approach where the model is prompted to chunk a document as a human would, i.e., guided by intent, structure, and meaning. This yields the most nuanced results but is costly and slow due to multiple LLM API calls and reasoning steps.
Chunking Parameters
Section titled “Chunking Parameters”Implementations of these approaches are available in a number of open-source libraries such as LangChain and Chonkie. While the choice of chunking approach determines how chunks are created, the configurable parameters it exposes control those outputs at a more granular level.
Most chunkers typically share two core parameters:
chunk_size- the maximum number of characters or tokens allowed in each chunk, which directly influences embedding granularity.chunk_overlap- the number of characters or tokens shared across adjacent chunks to preserve context continuity at chunk boundaries.
Recursive chunkers commonly introduce one additional parameter:
separators- a list of delimiters (e.g.,["\n\n", "\n", " ", ""]) that define the hierarchical split points.
Some providers may also expose algorithm-specific options. For example, LangChain’s text splitters include a strip_whitespaces parameter that trims leading and trailing whitespace to produce cleaner chunk boundaries. Most chunkers ship with reasonable defaults for advanced parameters, allowing users to only adjust the ones that matter for their use cases.
Together, the choice of chunking method and its configuration parameters define a chunking strategy, and modifying any component directly influences the resulting chunks and, consequently, the embeddings derived from them.
Chunking Evaluation
Section titled “Chunking Evaluation”Given the wide range of chunking methods and configuration options, selecting an optimal chunking strategy is challenging. Because document structures and contents vary, chunking cannot be treated as a fixed choice. Small adjustments in chunk size, overlap, separators, or other parameters can significantly affect retrieval performance. Different chunkers behave differently across data formats such as Markdown, code, or mixed-structure documents. Moreover, various downstream task requirements, such as retrieval precision, context length, latency constraints, and embedding cost, impose different demands on chunk granularity and structure. Therefore, systematic evaluation of chunking strategies is a critical step in data ingestion pipelines for RAG systems.
As one of the leading open-source vector database providers, Chroma (2024)5 states:
The choice of chunking strategy can have a significant impact on retrieval performance, with some strategies outperforming others by up to 9% in recall.
Despite the significance of chunking decisions, existing chunking libraries (such as LangChain and Chonkie) do not provide mechanisms for comparing or benchmarking chunking outputs across multiple strategies, creating a gap that our project aims to address.
Chunk Visualization
Section titled “Chunk Visualization”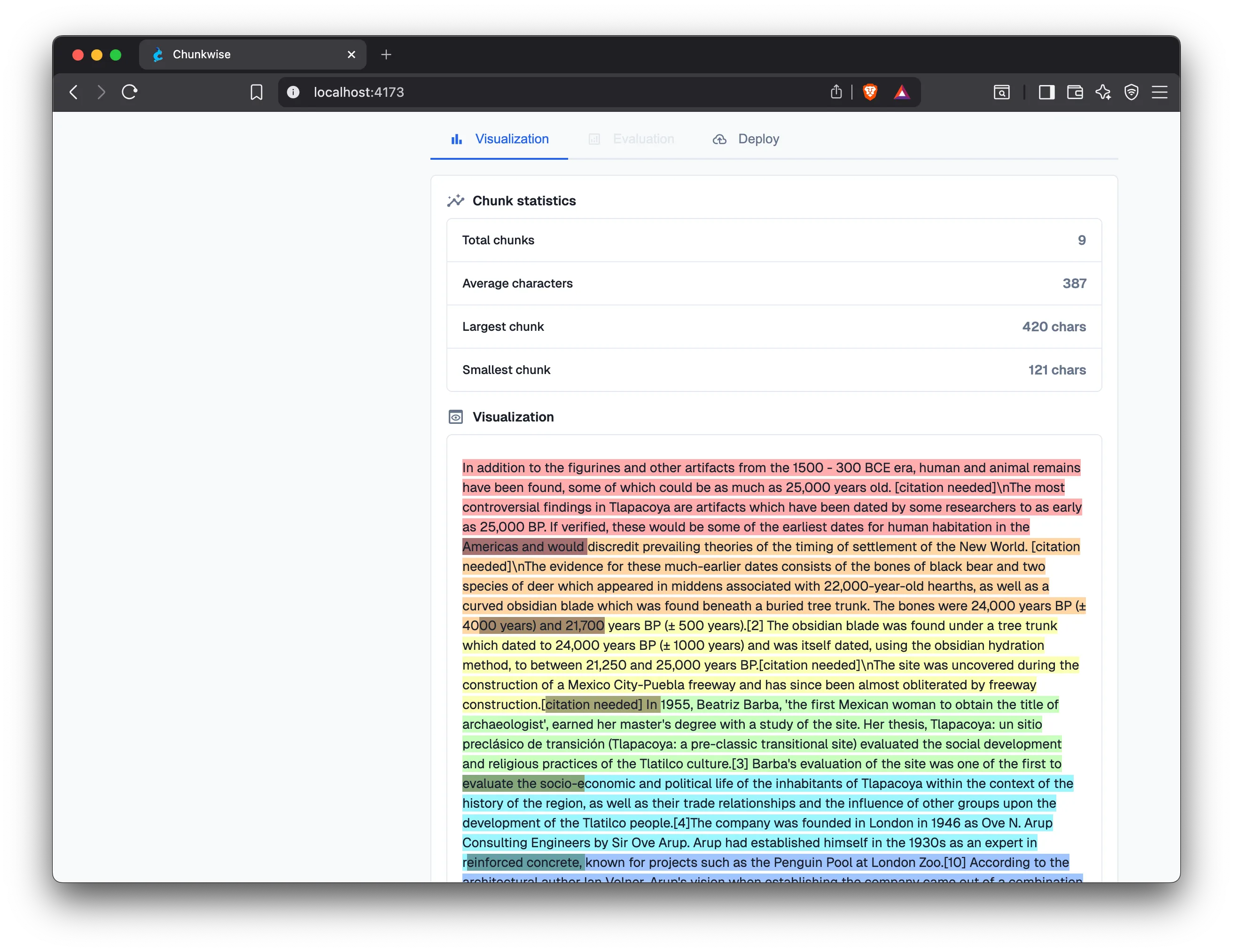
The most straightforward form of chunking evaluation is chunk visualization. Visual inspection allows users to qualitatively assess whether generated chunks have desirable properties, i.e., semantic coherence and structural integrity. Accompanying the visualization, chunk distribution statistics, including the total number of chunks, average chunk size, and minimum/maximum chunk lengths, provide quantitative insights into the shape of the resulting chunk set. These values also inform whether a strategy is compatible with a specific embedding model, particularly whether the largest chunk fits within the model’s maximum context window.
Retrieval-Based Evaluation
Section titled “Retrieval-Based Evaluation”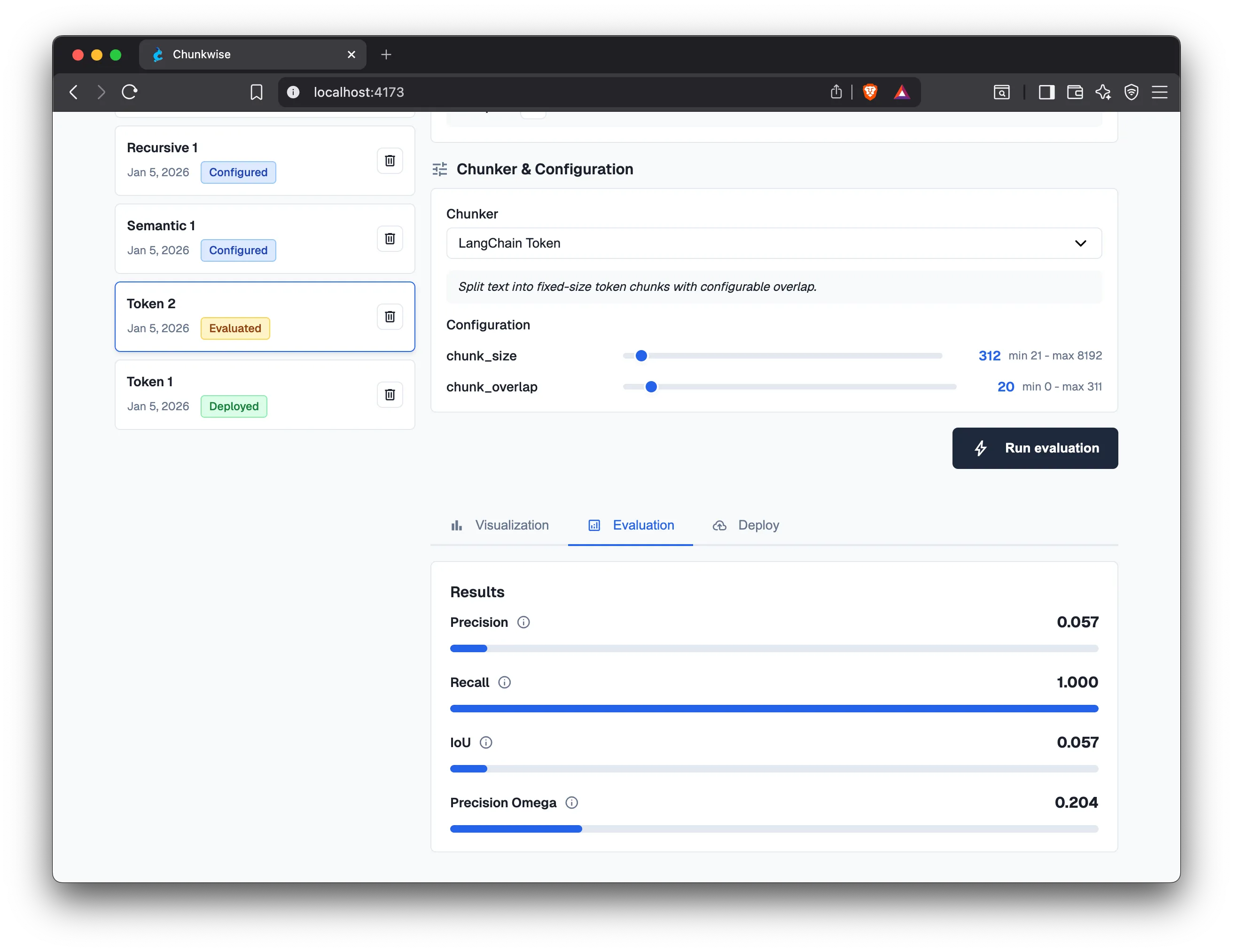
While chunk visualization and statistics offer descriptive insights, they do not directly measure how effectively a chunking strategy supports retrieval. Evaluating chunking through retrieval performance yields more actionable insights by revealing which strategies best surface relevant information for a specific retrieval task. Yet, despite chunking being a fundamental step in RAG data ingestion, research and tooling for retrieval-based evaluation of chunking strategies remain limited.
A key challenge is that commonly used Information Retrieval (IR) benchmarks, such as precision and recall, are typically computed at the whole-document level.6 In AI-assisted retrieval, however, relevance often exists at a finer granularity: only specific token spans within a document may be relevant to a query, and those spans may be distributed across multiple documents in the corpus. Therefore, effective retrieval for LLM-based systems depends not only on identifying the correct documents but also on retrieving the relevant token spans (chunks), which ultimately determine what the LLM consumes as context and the quality of its output.
Token-Level Metrics for Information Retrieval
Section titled “Token-Level Metrics for Information Retrieval”To address this gap, Chroma proposes a fine-grained, token-level evaluation framework for benchmarking retrieval accuracy and efficiency. They adapt classical IR metrics to operate at the token level:
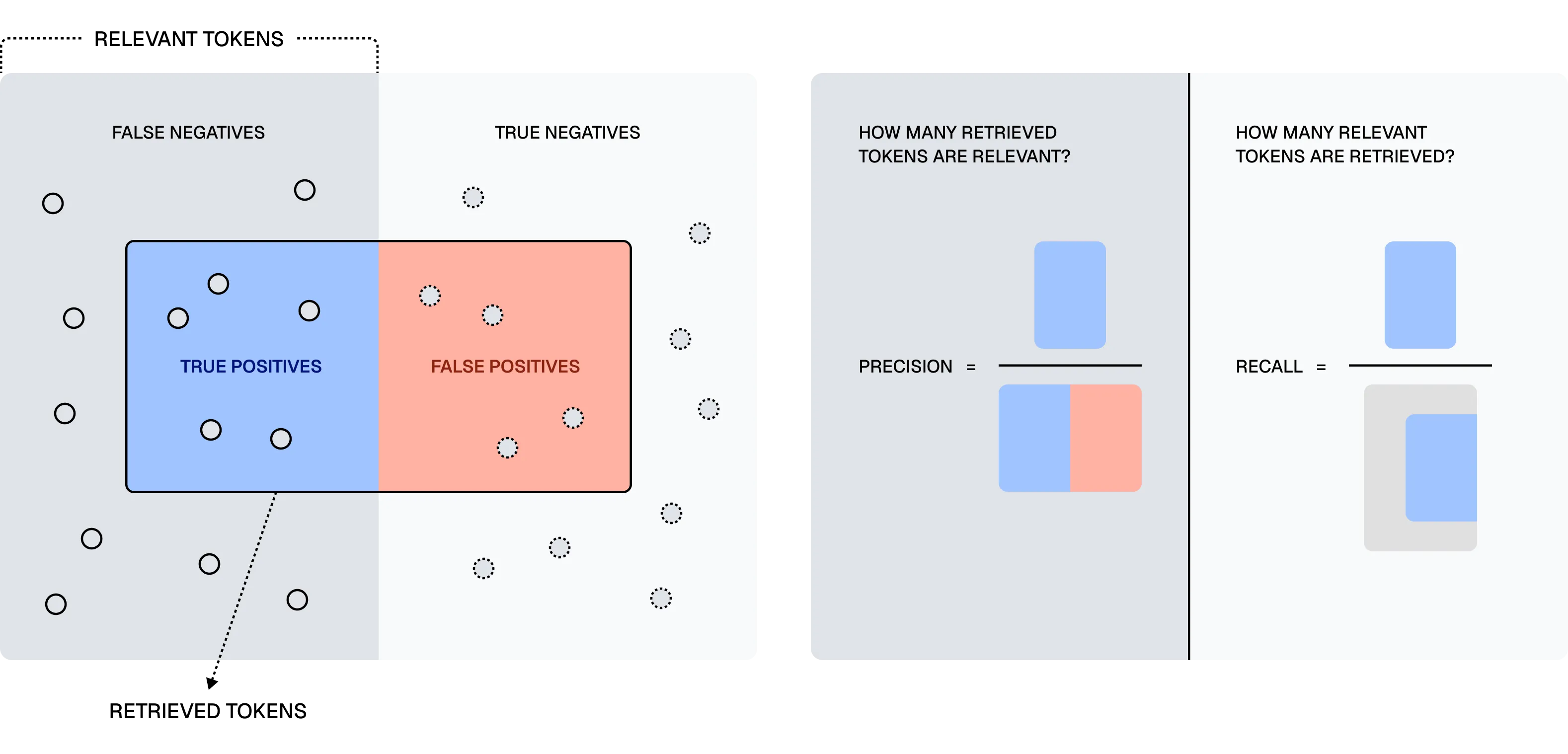
- Precision - Among all retrieved tokens, how many are relevant?
- Recall - Among all relevant tokens in the corpus, how many are retrieved?
In addition, they introduce a third, retrieval-specific metric:
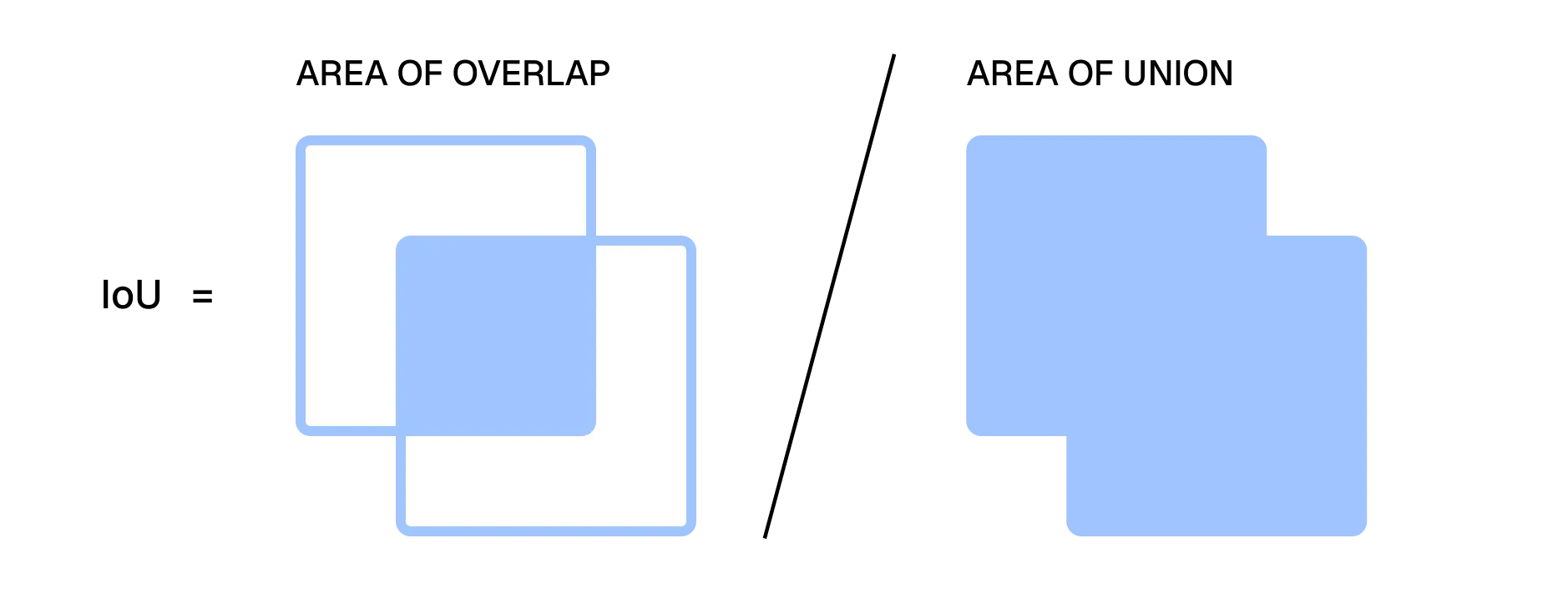
- Intersection over Union (IoU) - A token-level metric inspired by the Jaccard similarity coefficient in computer vision. Treating text chunks as “bounding boxes,” IoU measures the degree of overlap between the retrieved chunk boundaries and the ground-truth relevant token spans. Higher IoU indicates tighter alignment between chunk boundaries and relevant information.
Finally, they provide a fourth metric:
- Precision-Omega - A variant of precision obtained under the assumption of perfect recall. It serves as an upper bound on token efficiency and is therefore less statistically significant, but provides a best-case reference point.
Together, Precision, Recall, IoU, and Precision-Omega provide a comprehensive view of how effectively a chunking strategy surfaces the relevant information.
Evaluation Dataset and Ground Truth
Section titled “Evaluation Dataset and Ground Truth”The calculation of these metrics requires a dataset and a ground-truth reference set:
- Dataset - This may consist of the full corpus to be chunked, or a representative sample of it.
- Ground Truth (Generated via an LLM) - (1) factual queries about the dataset, and (2) corresponding relevant excerpts (expressed as token spans) from the dataset.
| Question | References | Corpus_Id |
|---|---|---|
| What did the hare say to the tortoise? | ”Do you ever get anywhere?” he asked with a mocking laugh. | The Hare & the Tortoise |
| What did the tortoise say to the hare? | ”Yes,” replied the Tortoise, “and I get there sooner than you think. I’ll run you a race and prove it.” | The Hare & the Tortoise |
| Who officiated the race? | So the Fox, who had consented to act as judge, marked the distance and started the runners off. | The Hare & the Tortoise |
| Why did the hare take a nap? | The Hare was soon far out of sight, and to make the Tortoise feel very deeply how ridiculous it was for him to try a race with a Hare, he lay down beside the course to take a nap until the Tortoise should catch up. | The Hare & the Tortoise |
| Who won the race? | The Hare now ran his swiftest, but he could not overtake the Tortoise in time. | The Hare & the Tortoise |
To improve the quality of the ground truth, two thresholds are applied to filter out queries with overly similar phrasing and excerpts that are insufficiently relevant to their associated query.
Once the ground truth is established, multiple chunking strategies can be evaluated against the same dataset. Users can interpret the metrics through the lens of their downstream tasks to choose the strategy that best aligns with their retrieval priorities.
For instance, a user who values maximum recall may prefer a strategy that retrieves more relevant information even at the cost of larger or more chunks. In contrast, a user who prioritizes context efficiency may choose a strategy that yields more precise chunks with higher precision or IoU. This chosen strategy can then be applied to the full corpus or to other datasets with similar characteristics.