Introducing Chunkwise
Chunkwise’s Solution
Section titled “Chunkwise’s Solution”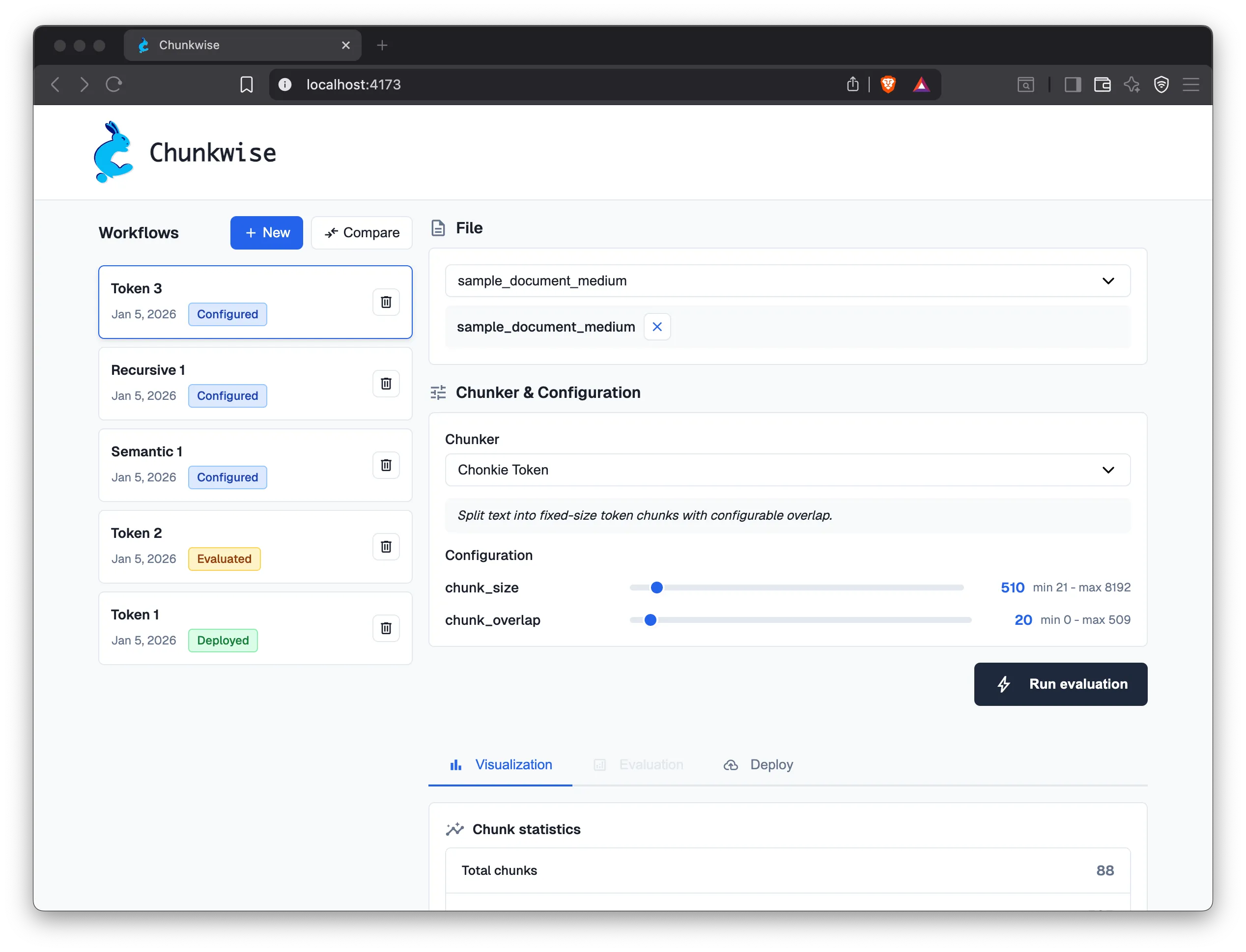
Chunkwise is an open-source, self-managed platform that addresses the chunking evaluation gap identified in existing solutions. It provides developers with systematic tools to compare chunking strategies and enables them to apply a selected strategy to the ingestion of a specific knowledge base via an easy-to-deploy ETL pipeline for downstream RAG systems.
Chunkwise employs a hybrid architecture that balances ease of use with data sovereignty. The client application runs locally in the user’s browsers, providing an intuitive interface for configuring chunking strategies and viewing evaluation results. The backend services are deployed and operated within the user’s Amazon Web Services (AWS) environment, allowing the user to retain full control over their infrastructure and data while benefiting from simplified, automated deployment and cost transparency.
Chunkwise is designed for teams seeking to optimize their chunking strategies for AI applications, particularly in settings where data privacy is a priority and where building and maintaining a fully custom solution would be resource-intensive. Specifically, it provides two core components:
Experimentation Platform
Section titled “Experimentation Platform”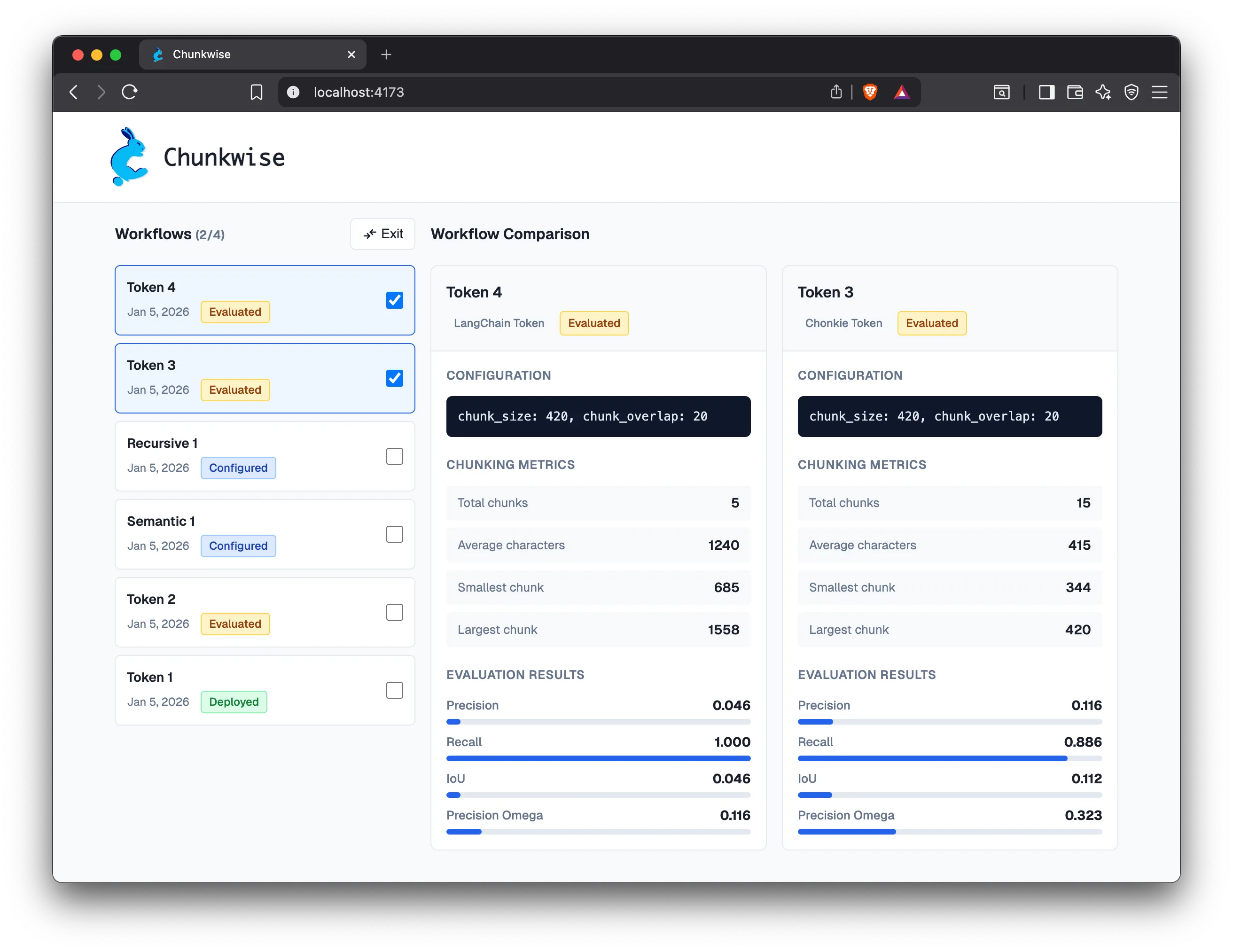
Chunkwise supports systematic evaluation of chunking strategies through chunk visualization, distribution statistics, and retrieval-based evaluation metrics. For qualitative inspection, Chunkwise adapts Chonkie’s visualization tool to provide a real-time representation of a chunked document, along with statistics summarizing the resulting chunks. This allows the user to identify issues such as inappropriate chunk boundaries and loss of semantic coherence. For quantitative evaluation, Chunkwise implements Chroma’s chunking evaluation framework to benchmark chunking strategies for retrieval performance.
AI-Focused ETL Pipeline
Section titled “AI-Focused ETL Pipeline”
Once a chunking strategy has been evaluated and selected, Chunkwise provides a deployable ETL pipeline that ingests a knowledge base stored in an Amazon S3 bucket and outputs vector embeddings and associated metadata to an Amazon RDS for PostgreSQL using the pgvector extension. Currently, the pipeline supports plain text (.txt) and Markdown (.md) files.
First, documents are ingested from the specified S3 bucket. Next, they are chunked according to the user’s selected chunking strategy. Each chunk is then embedded using OpenAI’s text-embedding-3-small model. Finally, the resulting vector embeddings and metadata are stored in the vector database, where they are available for downstream retrieval or export to other vector databases.
Existing Solutions
Section titled “Existing Solutions”Existing solutions for chunking evaluation and RAG data ingestion pipelines generally fall into three categories:
AI-Focused ETL Pipeline Platforms
Section titled “AI-Focused ETL Pipeline Platforms”
Chonkie, Vectorize, Unstructured, and LlamaCloud (by LlamaIndex) provide managed platforms for building AI-focused ETL pipelines. These platforms transform knowledge bases into vector embeddings through a particular workflow: data ingestion → parsing → chunking → embedding → export to a vector database.
In terms of chunking evaluation, Chonkie and Unstructured provide chunk visualization tools, while Vectorize provides a RAG evaluation sandbox that compares select chunking and embedding strategies using retrieval-based metrics. LlamaCloud does not currently provide any chunking evaluation features.
These platforms are well-suited for teams that require broad support for data sources, document formats, and embedding models, and are willing to rely on third-party managed services at the expense of reduced control and potential vendor lock-in.
AI Observability and Engineering Platforms
Section titled “AI Observability and Engineering Platforms”AI observability platforms (e.g., TruLens, Braintrust, and Arize Phoenix) focus on the observability and evaluation of AI applications by using traces to visualize the flow of data from user query to LLM response. AI engineering platforms (e.g., Langfuse, LangSmith, and Arize) provide infrastructure for deploying and iterating on AI applications with built-in observability and evaluation capabilities.
While these platforms excel at evaluating the overall performance of AI applications, they do not provide targeted evaluation of chunking strategies for retrieval. Hence, they are best suited for teams that have established an effective chunking strategy and seek to optimize other aspects of their AI applications.
DIY (Do it yourself)
Section titled “DIY (Do it yourself)”Open-source frameworks such as LlamaIndex and LangChain enable teams to build custom AI applications from the ground up by providing building blocks for constructing RAG data pipelines. They significantly reduce development time while preserving flexibility and control of a custom solution.
DIY approaches are appropriate for teams with sufficient engineering resources and expertise, particularly when data privacy and deep customization are top priorities. However, they require additional development effort to implement systematic chunking evaluation and visualization because the evaluation infrastructure must be built separately.